计算历史花名册
近日在分析企业员工的时候,需要计算企业成立到现在的人员变化情况,但手上只有最新的花名册数据,在不考虑员工调岗的情况下,用现有数据,生成一份历史花名册
例如:现有花名册
| 姓名 | 入职日期 | 员工状态 | 离职日期 |
|---|---|---|---|
| 员工 A | 2024/1/1 | 在职 | |
| 员工 B | 2024/2/5 | 离职 | 2024/9/1 |
生成历史数据
| 姓名 | 入职日期 | 员工状态 | 离职日期 | 备份时间 |
|---|---|---|---|---|
| 员工 A | 2024/1/1 | 在职 | 2024/1/1 | |
| 员工 A | 2024/1/1 | 在职 | 2024/1/2 | |
| ... | ... | ... | ... | |
| 员工 A | 2024/1/1 | 在职 | 2024/9/29 | |
| 员工 A | 2024/1/1 | 在职 | 2024/9/30 | |
| 员工 B | 2024/2/5 | 在职 | 2024/2/5 | |
| 员工 B | 2024/2/5 | 在职 | 2024/2/6 | |
| ... | ... | ... | ... | |
| 员工 B | 2024/2/5 | 在职 | 2024/8/31 | |
| 员工 B | 2024/2/5 | 离职 | 2024/9/1 | 2024/9/1 |
历史记录条数公式:=IF(离职日期,离职日期,TODAY())-入职日期 + 1 员工 A 重复条数:2024/9/30 - 2024/1/1 + 1 = 274 员工 B 重复条数:2024/9/1 - 2024/2/5 + 1 = 210
转换数据
创建类HistoryRoster,来处理数据
- 默认在创建类的时候,必须传入一个 Excel 文件路径,以及表名,默认为
Sheet1 self.df:- 参数:
excel_path:Excel 文件路径sheet_name:表名,默认为Sheet1skiprows:跳过的行数,默认为 0dtype:指定列的数据类型,默认为{"手机号": str, "工号": str, "证件号码": str, "员工序号": str}
python
class HistoryRoster:
def __init__(self, excel_path, sheet_name="Sheet1"):
self.df = pd.read_excel(
excel_path,
sheet_name=sheet_name,
skiprows=0,
dtype={"手机号": str, "工号": str, "证件号码": str, "员工序号": str})
self.repeated_df = pd.DataFrame()创建方法amend_data,用于修正数据
这里只对时间做了修正,也可以修正其他字段
python
def amend_data(self):
# 增加一列 '截至日期',如果离职日期为空,则填充为指定日期
specified_date = datetime.strptime('2024-09-30', '%Y-%m-%d').date()
self.df['截至日期'] = self.df['离职日期'].fillna(specified_date)
# 确保所有日期列为日期时间类型
self.df['入职日期'] = pd.to_datetime(self.df['入职日期'])
self.df['离职日期'] = pd.to_datetime(self.df['离职日期'])
self.df['截至日期'] = pd.to_datetime(self.df['截至日期'])创建方法repeated_day,用于根据天来重复数据
- 遍历原始数据,创建日期范围
- 根据日期范围,重复员工信息到每天
- 将重复的数据添加到
repeated_df中 - 重写离职日期和员工状态
- 返回
repeated_df
python
def repeated_day(self):
for _, row in self.df.iterrows():
# 创建日期范围
date_range = pd.date_range(
start=row['入职日期'],
end=row['截至日期'],
freq="D"
)
# 重复员工信息到每天
temp_df = pd.DataFrame([row] * len(date_range), index=date_range)
temp_df['备份时间'] = date_range
self.repeated_df = pd.concat([self.repeated_df, temp_df])
self.repeated_df["员工状态"] = self.repeated_df.apply(
lambda r: "已离职" if r['离职日期'] == r['备份时间'] else "在职", axis=1)
self.repeated_df["离职日期"] = self.repeated_df.apply(
lambda r: r["离职日期"] if r['离职日期'] == r['备份时间'] else None, axis=1)保存数据
保存数据到 Excel
python
def save_excel(self, name):
self.repeated_df.to_excel(name, index=False)保存数据到 MySQL
如果数据量较大,建议保存到 MySQL 数据库
创建 MySQL 数据库
sql
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键ID',
employee_name VARCHAR ( 255 ) NOT NULL COMMENT '姓名',
employee_id VARCHAR ( 50 ) NOT NULL COMMENT '工号',
hire_date DATE NOT NULL COMMENT '入职日期',
employee_type VARCHAR ( 50 ) NOT NULL COMMENT '员工状态',
confirmation_date DATE COMMENT '转正日期',
resignation_date DATE COMMENT '离职日期',
resignation_type VARCHAR ( 50 ) COMMENT '离职类型',
reason_for_resignation TEXT COMMENT '离职原因',
resignation_remarks TEXT COMMENT '离职备注',
backup_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '备份时间',
INDEX idx_employee_name ( employee_name ) -- 为姓名字段创建索引
);保存到 MySQL
python
def save_mysql(self):
new_columns = {
'姓名': 'employee_name',
'工号': 'employee_id',
'入职日期': 'hire_date',
'员工状态': 'employee_type',
'转正日期': 'confirmation_date',
'离职日期': 'resignation_date',
'离职类型': 'resignation_type',
'离职原因': 'reason_for_resignation',
'离职备注': 'resignation_remarks',
'备份时间': 'backup_time',
}
self.repeated_df = self.repeated_df.rename(columns=new_columns)
# MySQL数据库配置
db_config = {
'dialect': 'mysql+pymysql',
'username': 'root', # 替换为实际的用户名
'password': '123456', # 替换为实际的密码
'host': '127.0.0.1', # 数据库服务器地址
'port': '3306', # 端口号
'database': 'test' # 数据库名称
}
# 构建连接字符串
connection_string = "{dialect}://{username}:{password}@{host}:{port}/{database}".format(**db_config)
# 创建数据库引擎
engine = create_engine(connection_string)
# 表名
table_name = 'employees'
# 将DataFrame写入MySQL数据库
self.repeated_df.to_sql(name=table_name, con=engine, if_exists='append', index=False)完整代码
python
from datetime import datetime
import pandas as pd
from sqlalchemy import create_engine
"""
根据现有花名册数据,生成历史花名册
"""
class HistoryRoster:
def __init__(self, excel_path, sheet_name="Sheet1"):
self.df = pd.read_excel(
excel_path,
sheet_name=sheet_name,
skiprows=0,
dtype={"手机号": str, "工号": str, "证件号码": str, "员工序号": str})
self.repeated_df = pd.DataFrame()
def amend_data(self):
# 指定日期
specified_date = datetime.strptime('2024-09-13', '%Y-%m-%d').date()
# 增加一列 '截至日期',如果离职日期为空,则填充为指定日期
self.df['截至日期'] = self.df['离职日期'].fillna(specified_date)
# 确保所有日期列为日期时间类型
self.df['修改时间'] = pd.to_datetime(self.df['修改时间'])
self.df['创建时间'] = pd.to_datetime(self.df['创建时间'])
self.df['入职日期'] = pd.to_datetime(self.df['入职日期'])
self.df['司龄开始日期'] = pd.to_datetime(self.df['司龄开始日期'])
self.df['转正日期'] = pd.to_datetime(self.df['转正日期'])
self.df['离职日期'] = pd.to_datetime(self.df['离职日期'])
self.df['出生日期'] = pd.to_datetime(self.df['出生日期'])
self.df['毕业时间'] = pd.to_datetime(self.df['毕业时间'])
self.df['截至日期'] = pd.to_datetime(self.df['截至日期'])
# 修改列名
self.df = self.df.rename(columns={"id": "花名册ID", "部门名称": "部门"})
def repeated_year(self):
"""按年重复数据,每年最后一天"""
for _, row in self.df.iterrows():
# 创建日期范围
date_range = pd.date_range(
start=row['入职日期'],
end=row['截至日期'] + pd.offsets.YearEnd(0),
freq='YE'
)
# 重复员工信息到每年
temp_df = pd.DataFrame([row] * len(date_range), index=date_range)
temp_df['备份时间'] = date_range
self.repeated_df = pd.concat([self.repeated_df, temp_df])
self.repeated_df["员工状态"] = self.repeated_df.apply(
lambda r: "已离职" if r["离职日期"].year == r['备份时间'].year else "在职", axis=1)
self.repeated_df["离职日期"] = self.repeated_df.apply(
lambda r: r["离职日期"] if r["离职日期"].year == r['备份时间'].year else None, axis=1)
def repeated_month(self):
"""按月重复数据,每月最后一天"""
for _, row in self.df.iterrows():
# 创建日期范围
date_range = pd.date_range(
start=row['入职日期'],
end=row['截至日期'] + pd.offsets.MonthEnd(0),
freq='ME'
)
# 重复员工信息到每月
temp_df = pd.DataFrame([row] * len(date_range), index=date_range)
temp_df['备份时间'] = date_range
self.repeated_df = pd.concat([self.repeated_df, temp_df])
self.repeated_df["员工状态"] = self.repeated_df.apply(
lambda r: "已离职" if r['离职日期'] + pd.offsets.MonthEnd(0) == r['备份时间'] else "在职", axis=1)
self.repeated_df["离职日期"] = self.repeated_df.apply(
lambda r: r["离职日期"] if r['离职日期'] + pd.offsets.MonthEnd(0) == r['备份时间'] else None, axis=1)
def repeated_day(self):
"""按天重复数据"""
for _, row in self.df.iterrows():
# 创建日期范围
date_range = pd.date_range(
start=row['入职日期'],
end=row['截至日期'],
freq="D"
)
# 重复员工信息到每天
temp_df = pd.DataFrame([row] * len(date_range), index=date_range)
temp_df['备份时间'] = date_range
self.repeated_df = pd.concat([self.repeated_df, temp_df])
self.repeated_df["员工状态"] = self.repeated_df.apply(
lambda r: "已离职" if r['离职日期'] == r['备份时间'] else "在职", axis=1)
self.repeated_df["离职日期"] = self.repeated_df.apply(
lambda r: r["离职日期"] if r['离职日期'] == r['备份时间'] else None, axis=1)
def set_columns(self):
# 选择保留的列
history_columns = ['姓名', '工号', '入职日期', '员工状态', '转正日期', '离职日期',
'离职类型', '离职原因', '离职备注', '备份时间']
self.repeated_df = self.repeated_df[history_columns]
def save_mysql(self):
self.set_columns()
new_columns = {
'姓名': 'employee_name',
'工号': 'employee_id',
'入职日期': 'hire_date',
'员工状态': 'employee_type',
'转正日期': 'confirmation_date',
'离职日期': 'resignation_date',
'离职类型': 'resignation_type',
'离职原因': 'reason_for_resignation',
'离职备注': 'resignation_remarks',
'备份时间': 'backup_time',
}
self.repeated_df = self.repeated_df.rename(columns=new_columns)
# MySQL数据库配置
db_config = {
'dialect': 'mysql+pymysql',
'username': 'root', # 替换为实际的用户名
'password': '123456', # 替换为实际的密码
'host': '127.0.0.1', # 数据库服务器地址
'port': '3306', # 端口号
'database': 'test' # 数据库名称
}
# 构建连接字符串
connection_string = "{dialect}://{username}:{password}@{host}:{port}/{database}".format(**db_config)
# 创建数据库引擎
engine = create_engine(connection_string)
# 表名
table_name = 'employees'
# 将DataFrame写入MySQL数据库
self.repeated_df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
def save_excel(self, name):
self.set_columns()
self.repeated_df.to_excel(name, index=False)
if __name__ == '__main__':
history = HistoryRoster('花名册-20240927.xlsx', 'Sheet2')
print(history.df)
# history.repeated_year() # 按年
# history.repeated_month() # 按月
history.repeated_day() # 按天
# history.save_excel("历史花名册1.xlsx") # 保存到Excel
history.save_mysql() # 保存到MySQL
print(history.repeated_df)查询数据
最终采用的是按天重复数据,并保存到MySQL中,将数据的维度尽量精确到最小单位,这样有利于后续分析。 按年查询
sql
SELECT
employee_name 姓名,
employee_id 工号,
hire_date 入职日期,
employee_type 员工状态,
confirmation_date 转正日期,
resignation_date 离职日期,
resignation_type 离职类型,
reason_for_resignation 离职原因,
resignation_remarks 离职备注,
backup_time 备份时间
FROM employees
WHERE backup_time IN (
SELECT MAX(backup_time) AS last_day_of_year
FROM employees
GROUP BY YEAR(backup_time)
)
ORDER BY backup_time;按月查询
sql
SELECT
employee_name 姓名,
employee_id 工号,
hire_date 入职日期,
employee_type 员工状态,
confirmation_date 转正日期,
resignation_date 离职日期,
resignation_type 离职类型,
reason_for_resignation 离职原因,
resignation_remarks 离职备注,
backup_time 备份时间
FROM employees
WHERE backup_time IN (
SELECT MAX(backup_time) AS last_day_of_year
FROM employees
GROUP BY
)
ORDER BY backup_time;分析数据
在Excel中,用Power Query获取MySQL数据,用Power Pivot来分析数据
连接MySQL数据
- 创建连接
- 数据选项卡
- 获取数据-来自数据库
- 选择MySQL数据库
不同版本,操作路径可能会不一样,但基本都在数据选项卡下面,找到MySQL数据库
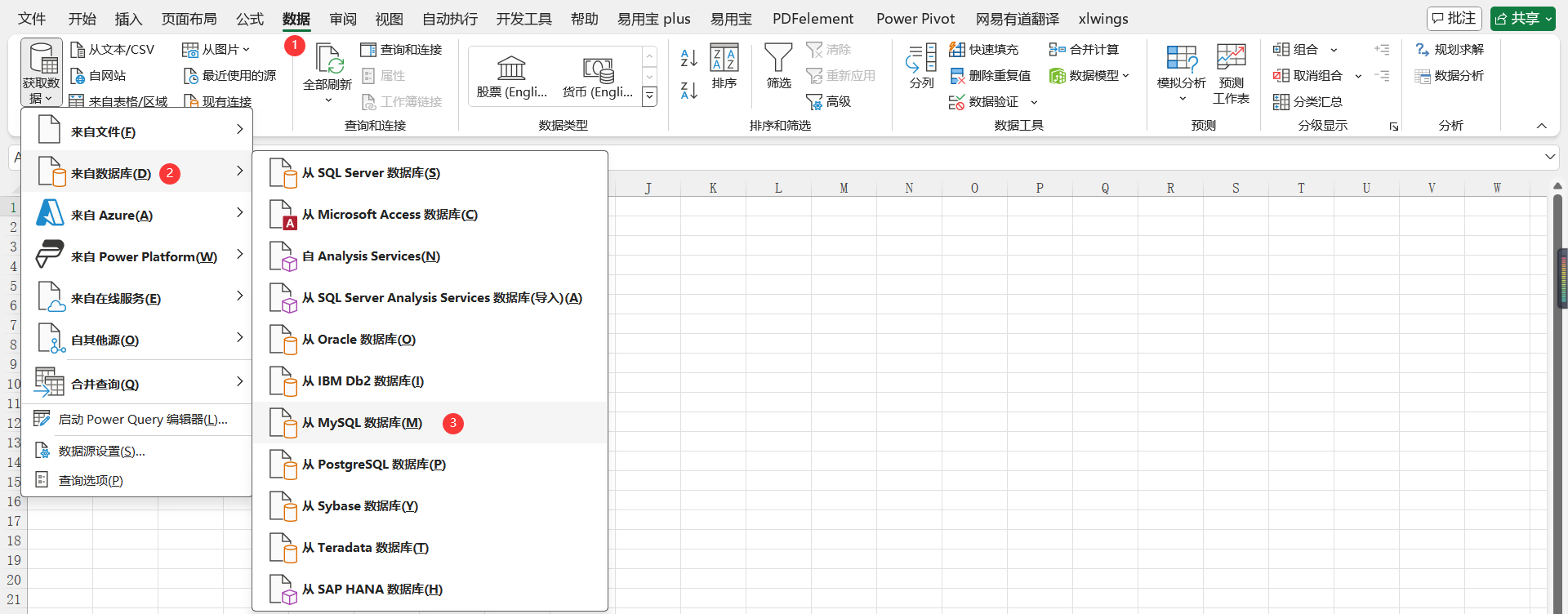
- 配置连接
使用按年查询的sql语句
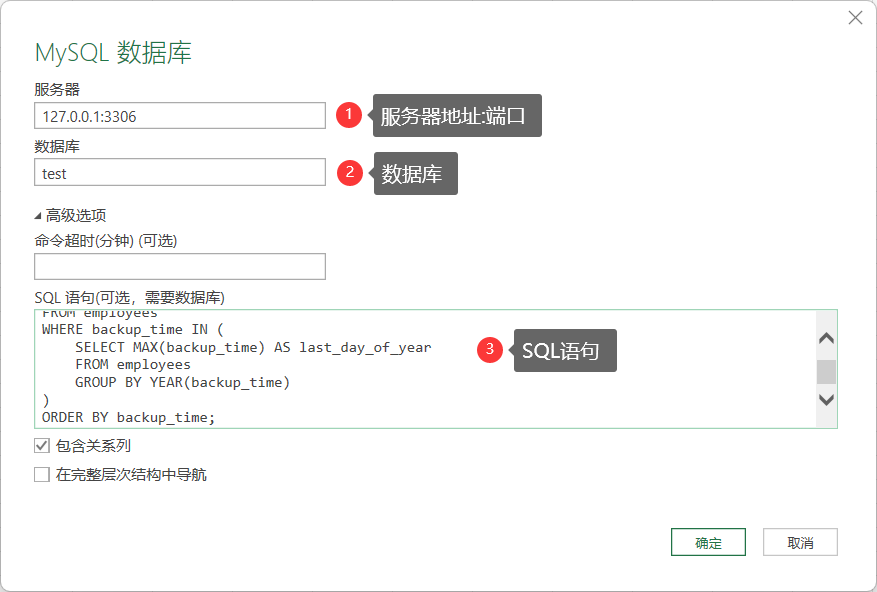
- 登录连接
- 进入Power Query
